Comprendiendo el Rendimiento del Hardware para el Aprendizaje Profundo usando la Multiplicación de Matrices como Referencia:
Descubra cómo se comparan las opciones de hardware de CPU, GPU y TPU en el rendimiento del aprendizaje profundo utilizando la multiplicación de matrices como referencia. Aprenda por qué los GFLOPs son cruciales en el entrenamiento de redes neuronales y cómo los diferentes dispositivos manejan cálculos a gran escala. Este análisis de NeuroTechNet ofrece perspectivas sobre la optimización de la elección de hardware para proyectos de inteligencia artificial y aprendizaje automático.
Rubén Guerrero
8/22/20244 min leer
Introducción
En el mundo del aprendizaje profundo, la elección del hardware adecuado puede influir dramáticamente en la velocidad y eficiencia de los procesos de entrenamiento de modelos. En NeuroTechNet, entendemos que diferentes tipos de hardware—CPUs, GPUs y TPUs—ofrecen distintos niveles de rendimiento, lo que impacta directamente en los plazos y costos de sus proyectos. Para ayudarle a tomar decisiones informadas, realizamos experimentos utilizando el rendimiento de la multiplicación de matrices medido en GFLOPs (Giga Operaciones de Punto Flotante por Segundo) como un indicador para comparar estas opciones de hardware.
En esta publicación, explicaremos por qué la multiplicación de matrices es un buen indicador del rendimiento en el entrenamiento de redes neuronales, analizaremos los resultados de nuestro experimento y discutiremos las implicaciones para sus proyectos de aprendizaje profundo.
|¿Por qué utilizar la multiplicación de matrices como un Proxy?
La multiplicación de matrices es una operación fundamental en el aprendizaje profundo, especialmente en el entrenamiento de redes neuronales. A continuación se explica por qué sirve como un excelente proxy para el rendimiento general del entrenamiento:
Son operación centrales en las redes neuronales:
Propagación hacia adelante: En cada capa de una red neuronal, se utiliza la multiplicación de matrices para transformar los datos de entrada al multiplicarlos por los pesos de la capa.
Propagación hacia atrás: Durante la retropropagación, los gradientes se calculan utilizando la multiplicación de matrices para ajustar los pesos, lo que permite que la red mejore el ajuste de los datos "aprenda".
Actualización de pesos: El paso final en un paso del entrenamiento, donde los pesos se actualizan en función de los gradientes, también depende de operaciones matriciales.
Intensidad computacional:
La multiplicación de matrices es computacionalmente intensiva y se realiza repetidamente a través de todas las capas tanto durante la propagación hacia adelante como hacia atrás. Por lo tanto, el rendimiento de esta operación está directamente relacionado con la velocidad general del entrenamiento.
Utilización del hardware:
El hardware moderno, como las GPU y TPU, está optimizado para tareas de procesamiento paralelo, como la multiplicación de matrices. Por lo tanto, medir el rendimiento de esta operación proporciona una imagen clara de cómo manejará el hardware el entrenamiento de redes neuronales.
Aplicabilidad en redes neuronales:
La multiplicación de matrices es especialmente relevante para las capas totalmente conectadas, comunes en muchas redes neuronales como las CNN y RNN, lo que la convierte en un proxy adecuado en varias arquitecturas.
El Experimento: Comparación del Rendimiento entre CPU, GPU y TPU
Para comparar el rendimiento de una CPU, una GPU y una TPU, llevamos a cabo un experimento en el que medimos los GFLOPs alcanzados durante tareas de multiplicación de matrices de diferentes tamaños. Este experimento fue diseñado para reflejar los tipos de operaciones comunes en los procesos de entrenamiento de aprendizaje profundo.
Estos son los dispositivos que utilizamos:
CPU: Intel(R) Xeon(R) CPU @ 2.00GHz
GPU: NVIDIA T4
TPU: Google TPU v2
Análisis de los Resultados
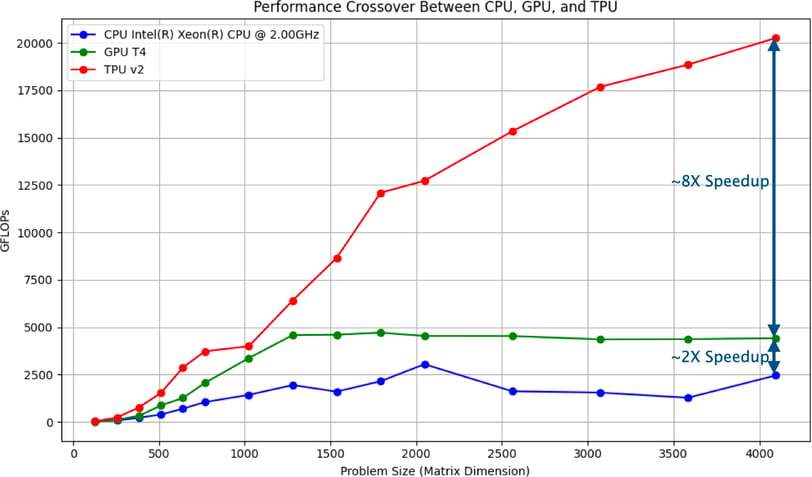
Los resultados del experimento se resumen en el gráfico al inicio de esta publicación.
Observaciones Clave
Rendimiento del CPU:
El CPU mostró un aumento modesto en el rendimiento a medida que aumentaba el tamaño de la matriz, pero alcanzó una meseta temprano, reflejando su naturaleza de propósito general. Los CPUs son versátiles pero nó están especializados para las exigencias intensas del aprendizaje profundo, lo que lleva a un menor rendimiento total en GFLOPs.
Rendimiento del GPU:
El GPU superó significativamente al CPU, alcanzando mayores GFLOPs, especialmente a medida que aumentaban los tamaños de las matrices. Sin embargo, el rendimiento se estabilizó, indicando que el GPU alcanzó su máxima eficiencia para estas tareas. Los GPUs son ideales para el procesamiento en paralelo, lo que los hace muy adecuados para muchas cargas de trabajo de aprendizaje profundo.
Rendimiento del TPU:
El TPU mostró el mayor rendimiento en todos los tamaños de matrices, con GFLOPs que continuaron escalando a medida que aumentaba el tamaño de las matrices. El TPU logró aproximadamente 8 veces el rendimiento del CPU y 2 veces el rendimiento del GPU en el tamaño de matriz más grande probado, demostrando su capacidad superior para las tareas de aprendizaje profundo.
Por qué Importan Estos Resultados:
Para Tareas Pequeñas a Moderadas: La GPU ofrece un aumento significativo en el rendimiento en comparación con la CPU, lo que la convierte en la opción más rentable para muchas aplicaciones de aprendizaje profundo.
Para Aprendizaje Profundo a Gran Escala: La TPU supera tanto a la CPU como a la GPU, especialmente en tareas a gran escala. Su capacidad para manejar grandes volúmenes de cálculos rápidamente la hace invaluable para el entrenamiento de modelos grandes o para trabajar con conjuntos de datos extensos.
Conclusión
La multiplicación de matrices, medida en GFLOPs, proporciona un indicador claro y efectivo para comprender el rendimiento computacional de diferentes opciones de hardware en el entrenamiento de redes neuronales. Los resultados de nuestro experimento muestran que, si bien las CPUs son versátiles y las GPUs ofrecen un fuerte aumento en el rendimiento, las TPUs son insuperables para las cargas de trabajo de aprendizaje profundo a gran escala.
En NeuroTechNet, aprovechamos estos conocimientos para ayudar a nuestros clientes a optimizar sus opciones de hardware, asegurando que sus modelos de aprendizaje profundo se entrenen de manera eficiente y efectiva. Ya sea que estés comenzando con la IA o estés escalando para manejar modelos más complejos, comprender estas dinámicas de hardware es crucial para mantener la competitividad en el campo, que evoluciona rápidamente, del aprendizaje automático.
Si tienes alguna pregunta o te gustaría explorar cómo aplicar estos conocimientos a tus proyectos específicos, no dudes en contactarnos en NeuroTechNet!
Redes Sociales
¡Mantente conectado con las últimas innovaciones—sigue a NeuroTechNet en las redes sociales!
CONTACTANOS
NOTICIAS
+57 3242220660
© 2024. All rights reserved.