The Power of Supervised Machine Learning with Proprietary Optimization Strategies
Explore how NeuroTechNet leverages proprietary smart optimization strategies to enhance the power of supervised machine learning. In this blog, we demonstrate how cutting-edge machine learning models can drive transformational change across industries like healthcare, finance, manufacturing, and retail. Discover how our advanced techniques deliver superior performance in model training, improve accuracy, and extract deeper insights from the data. Whether you're looking to optimize operations, predict outcomes, or gain actionable insights, NeuroTechNet's innovative solutions are designed to help businesses unlock the full potential of their data.
SOFTWARE-HARDWARE INTEGRATION
Ruben Guerrero
9/26/20245 min read
In today's rapidly evolving technological landscape, industries are continuously looking for ways to gain competitive advantages and streamline their processes. Supervised machine learning (ML) is emerging as a game-changing technology capable of driving breakthroughs across various sectors. At NeuroTechNet, we are not just applying machine learning; we are developing proprietary smart optimization strategies that enhance performance and generate deeper insights into the training landscape.
Our optimization strategies allow us to push the boundaries of what machine learning models can achieve, giving our clients a distinct competitive edge. Whether the application is in healthcare, finance, manufacturing, or retail, our advanced techniques ensure that the models are trained efficiently, leading to superior predictive power and actionable insights.
Introduction to the Dataset: Iris Flowers and Beyond
The Iris dataset is a well-known classification dataset often used in the field of machine learning. The dataset consists of 150 samples, each representing a different type of iris flower (Setosa, Versicolor, and Virginica). For each sample, four features are provided: sepal length, sepal width, petal length, and petal width. The task is to classify each flower into one of the three species based on these features.
While this dataset deals with flowers, NeuroTechNet’s proprietary optimization strategies can be applied across any industry. Whether you're detecting defects in a manufacturing process, predicting patient outcomes in healthcare, or classifying financial transactions as fraudulent, our models are optimized for maximum performance and insight.


Here, we introduce the three classes of the dataset:
Setosa: These flowers are easily distinguishable by their smaller petal length and width.
Versicolor: A bit more complex, this flower has features that overlap with the Virginica class.
Virginica: The largest flower in the dataset, with generally larger petal and sepal measurements.
These distinctions allow us to test various classification models. However, NeuroTechNet’s proprietary optimizations ensure that the models achieve better convergence and higher accuracy compared to traditional methods, making them suitable for real-world industry applications.
Industry Applications and Benefits
Supervised learning is widely applicable across industries. NeuroTechNet’s proprietary optimization strategies take these benefits further by improving the performance of models in terms of speed, accuracy, and interpretability. Here are some key areas where our advanced methods deliver tremendous value:
Healthcare & Biotech: In healthcare, we can train a model to classify patient conditions based on features such as blood pressure, cholesterol levels, and genetic markers. Our optimization strategies ensure that the models converge faster and deliver more accurate results, making them ideal for early diagnosis and personalized medicine. For example, our proprietary methods have proven effective in reducing false positives and improving diagnostic precision in clinical trials.
Finance: In the financial sector, models trained on transaction data can detect fraud with high accuracy. Our optimization strategies allow financial institutions to deploy fraud detection models that not only perform well but also adapt dynamically to new types of fraud, improving security in real time.
Manufacturing: The principles of classification apply seamlessly to predictive maintenance and quality control. NeuroTechNet’s optimizations ensure that models trained on sensor data can identify equipment failures earlier, helping businesses avoid costly downtime. Our methods excel at distinguishing between true machine anomalies and harmless noise, thanks to enhanced landscape insights from our optimization techniques.
Retail & E-commerce: Predicting customer behavior and dynamic pricing can be approached using the same ML methodologies. Our models are optimized to process large datasets quickly and deliver real-time predictions, allowing retailers to maximize revenue and enhance customer satisfaction. With the ability to fine-tune hyperparameters automatically, our proprietary strategies ensure businesses stay ahead in a competitive marketplace.
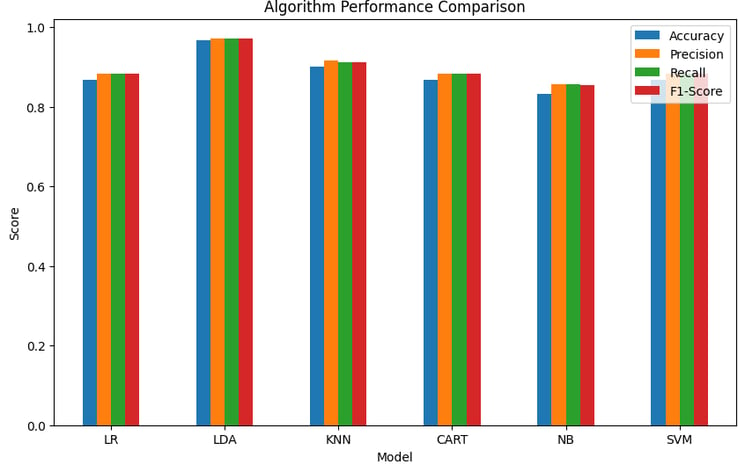
Algorithm Performance Comparison with Proprietary Optimizations
We evaluated multiple classification algorithms to demonstrate their performance in real-world applications. Figure 1 (above) displays a performance comparison across four essential metrics: Accuracy, Precision, Recall, and F1-Score for various classification methods, including Logistic Regression, LDA, KNN, Decision Trees, Naive Bayes, and SVM.
At NeuroTechNet, we use smart optimization strategies that not only train models faster but also extract more information from the training landscape. This deeper understanding of the optimization process results in better-performing models across the board. For instance, SVM and LDA exhibit outstanding performance across all metrics, particularly in applications where minimizing false negatives or false positives is critical—such as fraud detection or medical diagnostics.
Our proprietary techniques ensure that models learn faster and more effectively, which translates to fewer training cycles and a greater ability to generalize to unseen data.
Accuracy Comparison with Cross-Validation
Figure 2 shows the distribution of accuracy scores across models using cross-validation. This method is used to ensure that the model's performance is consistent across different subsets of the data. NeuroTechNet’s proprietary optimization strategies allow models to maintain high performance, even when subjected to different data splits.
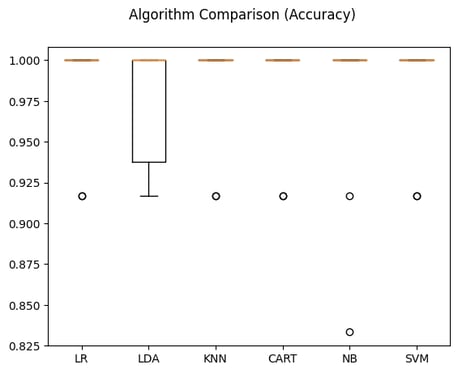
Cross-validation plays a vital role in verifying the reliability of machine learning models, especially in critical applications like healthcare or finance, where the cost of a false prediction can be high. NeuroTechNet’s optimizations further enhance this process by identifying and adjusting to nuances in the training data, resulting in more stable models.
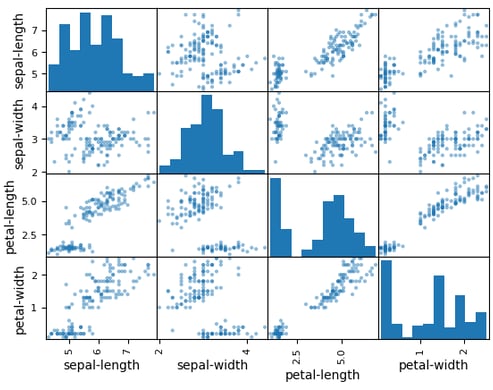
Data Correlations and Insights
Before applying machine learning algorithms, understanding the relationships between variables is crucial. Figure 3 illustrates the correlations between different features in the dataset, highlighting the strength of the relationships between input variables.
Our proprietary optimization strategies enhance this process by automatically identifying the most important features, allowing businesses to refine their models without needing extensive manual intervention. This is especially useful in industries like manufacturing, where hundreds of sensor readings may be analyzed, but only a few are truly predictive of machine failure.
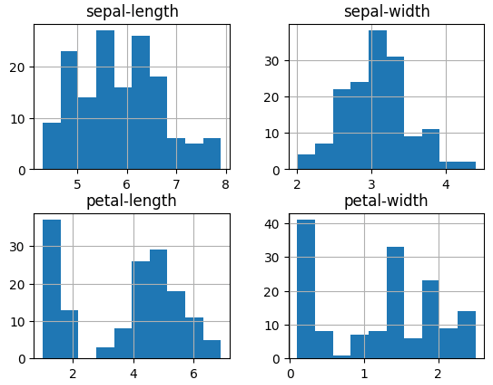
Data Distribution for Better Model Training
Figure 4 showcases the distribution of features within the dataset. NeuroTechNet’s optimizations ensure that models are trained on well-distributed data, preventing overfitting and ensuring generalization to new data. This is crucial for sectors like e-commerce, where a skewed dataset can lead to poor customer insights or biased predictions.
In applications such as personalized marketing, well-distributed data ensures that models do not overfit to particular customer segments, allowing for more effective customer segmentation and targeted marketing strategies.
Outlier Detection and Enhanced Training
Identifying outliers in data is another critical step in building reliable machine learning models. Figure 5 demonstrates outliers in various features using boxplots.
Outliers can significantly affect model performance, but at NeuroTechNet, we apply optimization strategies that adapt to noisy and incomplete data. For instance, in finance, detecting outliers in transaction patterns can indicate potential fraud, while in manufacturing, outliers may reveal equipment malfunctions. By detecting and addressing outliers, we ensure that the training data fed into the models is clean and representative, which boosts performance.
Conclusion: Partner with NeuroTechNet for Smarter, Faster ML Solutions
At NeuroTechNet, we go beyond standard machine learning approaches. Our proprietary smart optimization strategies drive superior model performance, offering faster training, better generalization, and deeper insights from the data. Whether you're looking to optimize your processes, gain insights into customer behavior, or predict outcomes with greater precision, our cutting-edge technologies and expert team are here to help.
If you're interested in how proprietary machine learning optimizations can transform your industry, contact us today to start a partnership that will unlock the true value of your data. Together, we can help you move from data to actionable insights, empowering your business to thrive in the digital age.
Social Networks
Stay connected with the latest innovations—follow NeuroTechNet on social media!
CONTACT
NEWS
+57 3242220660
© 2024. All rights reserved.