Understanding Hardware Performance for Deep Learning with Matrix Multiplication as a Proxy
Discover how CPU, GPU, and TPU hardware options compare in deep learning performance using matrix multiplication as a proxy. Learn why GFLOPs are crucial in neural network training and how different devices handle large-scale computations. This analysis from NeuroTechNet offers insights into optimizing hardware choices for AI and machine learning projects.
SOFTWARE-HARDWARE INTEGRATION
Ruben Guerrero
8/22/20243 min read
Introduction
In the world of deep learning, choosing the right hardware can dramatically influence the speed and efficiency of your model training processes. At NeuroTechNet, we understand that different types of hardware—CPUs, GPUs, and TPUs—offer varying levels of performance, which directly impacts your project timelines and costs. To help you make informed decisions, we experimented using matrix multiplication performance measured in GFLOPs (Giga Floating-Point Operations per Second) as a proxy to compare these hardware options.
In this post, we'll explain why matrix multiplication is a good proxy for neural network training performance, analyze the results from our experiment, and discuss the implications for your deep learning projects.
Why Use Matrix Multiplication as a Proxy?
Matrix multiplication is a cornerstone operation in deep learning, especially in the training of neural networks. Here’s why it serves as an excellent proxy for overall training performance:
Core Operation in Neural Networks:
Forward Propagation: In each layer of a neural network, matrix multiplication is used to transform the input data by multiplying it with the layer's weights.
Backward Propagation: During backpropagation, the gradients are computed using matrix multiplication to adjust the weights, enabling the network to learn.
Weight Updates: The final step in training, where the weights are updated based on the gradients, also relies on matrix operations.
Computational Intensity:
Matrix multiplication is computationally intensive and is performed repeatedly across all layers during both forward and backward propagation. Thus, the performance of this operation is directly linked to the overall speed of training.
Hardware Utilization:
Modern hardware, like GPUs and TPUs, are optimized for parallel processing tasks such as matrix multiplication. Therefore, measuring the performance of this operation provides a clear picture of how well the hardware will handle neural network training.
Applicability Across Neural Networks:
Matrix multiplication is especially relevant for fully connected layers, common in many neural networks like CNNs and RNNs, making it a suitable proxy across various architectures.
The Experiment: Comparing CPU, GPU, and TPU Performance
To compare the performance of a CPU, a GPU, and a TPU, we conducted an experiment where we measured the GFLOPs achieved during matrix multiplication tasks of varying sizes. This experiment was designed to reflect the types of operations common in deep learning training processes.
Here are the devices we used:
CPU: Intel(R) Xeon(R) CPU @ 2.00GHz
GPU: NVIDIA T4
TPU: Google TPU v2
Analyzing the Results
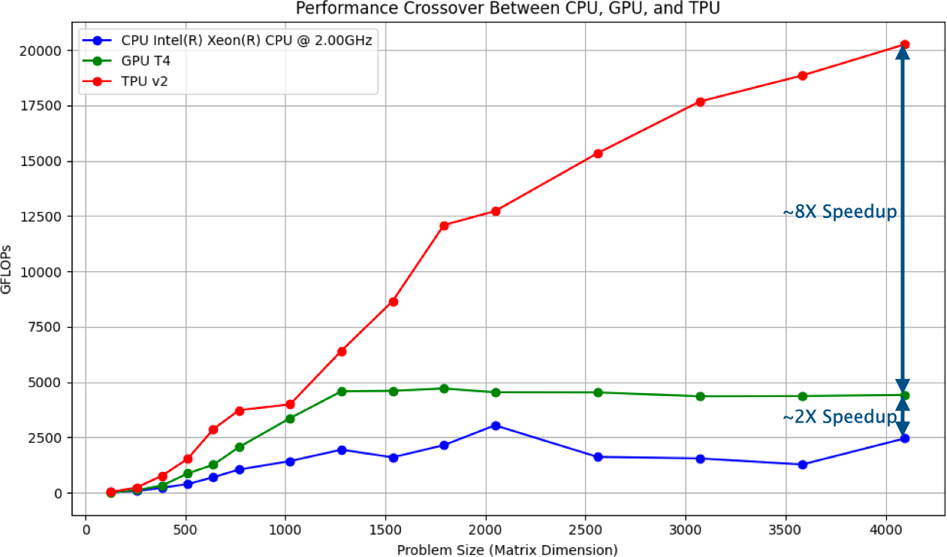
The results from the experiment are summarized in the graph at the beginning of this post.
Key Observations
CPU Performance:
The CPU showed a modest increase in performance as the matrix size increased but plateaued early, reflecting its general-purpose nature. CPUs are versatile but not specialized for the intense demands of deep learning, leading to lower overall GFLOPs.
GPU Performance:
The GPU outperformed the CPU significantly, achieving higher GFLOPs, especially as the matrix sizes grew. However, the performance leveled off, indicating the GPU reached its peak efficiency for these tasks. GPUs are well-suited for parallel processing, which makes them ideal for many deep learning workloads.
TPU Performance:
The TPU displayed the highest performance across all matrix sizes, with GFLOPs continuing to scale as the matrix sizes increased. The TPU achieved approximately 8x the performance of the CPU and 2x the performance of the GPU at the largest matrix size tested, showcasing its superior capability for deep learning tasks.
Why These Results Matter:
For Small to Moderate Tasks: The GPU offers a significant performance boost over the CPU, making it the more cost-effective choice for many deep learning applications.
For Large-Scale Deep Learning: The TPU outshines both the CPU and GPU, particularly for large-scale tasks. Its ability to handle massive computations quickly makes it invaluable for training large models or working with extensive datasets.
Conclusion
Matrix multiplication, as measured in GFLOPs, provides a clear and effective proxy for understanding the computational performance of different hardware options in neural network training. The results of our experiment show that while CPUs are versatile and GPUs provide a strong boost in performance, TPUs are unmatched for large-scale deep learning workloads.
At NeuroTechNet, we leverage these insights to help our clients optimize their hardware choices, ensuring that their deep learning models are trained efficiently and effectively. Whether you're just starting with AI or you're scaling up to handle more complex models, understanding these hardware dynamics is crucial for staying competitive in the rapidly evolving field of machine learning.
If you have any questions or would like to explore how these insights can be applied to your specific projects, feel free to reach out to us at NeuroTechNet!
Social Networks
Stay connected with the latest innovations—follow NeuroTechNet on social media!
CONTACT
NEWS
+57 3242220660
© 2024. All rights reserved.